


(This is the third chapter of the first volume of The Scientific Experience, by Herbert Goldstein, Jonathan L. Gross, Robert E. Pollack and Roger B. Blumberg. The Scientific Experience is a textbook originally written for the Columbia course "Theory and Practice of Science". The primary author of "Measurement" is Jonathan L. Gross, and it has been edited and prepared for the Web by Blumberg. It appears at MendelWeb, for non-commercial educational use only. Although you are welcome to download this text, please do not reproduce it without the permission of the authors.)
This time the answer is yes. Even though the Celsius scale is not a ratio scale, when one uses it to measure temperature change, it becomes a ratio scale. When you are measuring relative difference, the value of zero represents no difference; zero is then no longer an arbitrary reference point in the scale, but one with physical and psychological meaning. In particular, the amount of energy required to raise the temperature, say, of one cubic centimeter of water, ten degrees is twice as great as the amount needed to raise it five degrees. Moreover, although finger-dipping estimates are not as precise or reliable as thermometer readings, people can scale gross differences of temperature within a suitable range of human perception.
The concepts of nominal, ordinal, and interval scale apply to what is possibly only a single dimension of a multivariate observation. Multidimensional measurements and classifications are common. For instance, we might classify individuals according to age and sex, thereby combining an interval scale on one dimension with a nominal scale on the other. In Chapter 7 we shall discuss some instances when two or more ordinal scales are combined to form a multidimensional scale, the ordinality might partially break down, because subject A might rate higher than subject B on scale 1, while subject B rates higher than subject A on scale 2.
3.2 What observations can you trust?
Certain attributes are thought desirable in just about any method of observation. First of all, a method is said to be reliable if its repetition under comparable circumstances yields the same result. In general, unreliable observation methods are not to be trusted in the practice of science, and theories are not accepted on the basis of irreproducible experiments. Reliability is consistency, and it is perhaps the measurement quality most responsible for yielding scientific knowledge that is "public".
In the natural sciences, the criterion of reproducibility is frequently easy to meet. For instance, two samples of the same chemical substance are likely to be essentially identical, if they are reasonably free of impurities. By way of contrast, this standard often introduces some problems of experimental design into the medical sciences. You cannot expect to apply the same treatment many times to the same patient, for a host of reasons. Among them, the patient's welfare is at stake, and each treatment might change the patient's health. Nonetheless, in medicine, even when you cannot hope to reuse the exact same subject, there is generally some hope of finding comparable subjects. [2]
In some of the social sciences, the problem of achieving reproducibility often seems extreme. The first visit of an anthropologist to a community may well change the community. Similarly, widespread publication of the results of a political poll might induce a change of voter sentiment. Nonetheless, for the findings to be regarded as scientific, whoever publishes them must accept the burden of presenting them in a manner that permits others to test them.
The intent to be accurate or impartial is not what makes a discipline a science. Conscientious reporting or disinterested sampling is not the basis for scientific acceptance. Reproducibility is what ultimately counts. Outstanding results are often obtained by persons with a stake in a particular outcome. For instance, a manufacturer of pharmaceuticals might have a large financial stake in the outcome of research into the usefulness and safety of a particular drug. Academic scientists usually have a greater professional benefit to be gained from "positive" results than from "negative" results; it would usually be considered more noteworthy to obtain evidence for the existence of some particle with specified properties than to gather evidence that it does not exist.
An accurate measurement method is one that gives the measurer the correct value or very close to it. An unreliable method cannot possibly be accurate, but consistency does not guarantee accuracy. An incorrectly calibrated thermometer might yield highly consistent readings on an interval scale, all inaccurate. By way of analogy, a piece of artillery that consistently overshoots by the same amount is reliable, but inaccurate. Accuracy means being on target.
As a practical matter, reliably inaccurate measurements are often preferable to unreliably inaccurate ones, because you might be able to accurately recalibrate the measuring tools. An extreme analogy is that a person who always says "No" for "Yes", and vice versa, gives you far more information, once you understand the pathology, than a person who lies to deceive, or than one who gives random answers.
Measurements on an ordinal scale are regarded as reliable if they are consistent with regard to rank. For instance, if we decide that when two soldiers meet, the one who salutes first is the one of higher rank, then our method is highly reliable, because there is a carefully observed rule about who salutes first. Our decision method happens to be completely inaccurate, because it is the person of lower rank who must salute first.
If the scale is nominal, we would appraise the reliability of a classificatory method by the likelihood that the subjects of the experiment would be reclassified into the same categories if the method were reapplied.
Consider now, the reliability of a classification of living species into either the plant kingdom or the animal kingdom according to whether they were observed to be stationery or mobile. This is not an accurate method, since coral animals are apparently stationery, and sagebrush is seemingly mobile. Moreover, not all living species belong to either the plant kingdom or the animal kingdom, so the problem of discernment is not even well-posed. A further complication is that some species, such as butterflies, have a stationary phase and a mobile phase. However, the issue is only whether whatever method of observation we apply to distinguish between stationariness and mobility produces the same answer repeatedly for members of the same species.
We can rate the reliability of a measurement method according to a worst case or to an average case criterion. For interval scale measurements, the reliability is most commonly appraised according to relative absence of discrepancy, and it is given the special name precision. Discrepancy of a millimeter is highly precise if the target is a light year away. It would be overwhelmingly imprecise if we were measuring the size of a molecule. A common measure of precision is the number of significant digits in a decimal representation of the measurement.
Associated with accuracy is the concept of validity. We say that a measurement is valid if it measures what it purports to measure. A method that is direct and accurate, such as measuring distance by a correctly calibrated ruler, is always valid. However, when the measurement is indirect, it might be invalid, no matter how consistent or precise it is.
For example, suppose we attempted to measure how much of a long passage of text an individual had memorized by the number of complete sentences of that passage that the person could write in ten minutes. Although this measure might be consistent, it is invalid in design, since it gives too much weight to handwriting speed. It is also an invalid measure of handwriting speed, because it gives too much weight to memorization.
The phlogiston theory is another example of precise invalidity. Before it was understood that combustion is rapid oxidation, it was thought that when a material ignites, it loses its "phlogiston". The amount of phlogiston lost was reckoned to be the difference in weight between the initial substance and its ash residue. Do you know what accounts for the lost weight?
The question of validity is often enshrouded in semantics. For instance, there is a purported method of measuring "intelligence" according to the frequency with which a person uses esoteric words. The burden of proof that what is measured by such a test, or by any other test, is correlated to other kinds of performance commonly associated with the word "intelligence" lies on the designer of that measure.
In the absence of proof, using the word "intelligence" for that property is purely semantic inflation of a single trait of relatively minor importance into a widely admired general kind of superiority. Surely the importance of the concept of intelligence depends on its definition as something more than a property measured by such a simplistic test. Indeed it might be preferable not to try to reduce a complex property such as intelligence to a single number. Suppose that someone was far above average in verbal skills and far below average in mathematical skills: would it be reasonable to blur the distinction between that person and someone else who was average in both kinds of skills?
Criticism of proposed models -- sometimes based on empirical results, sometimes based on intuition or "thought experiments" --is an important part of scientific activity. Of course, every practicing scientist knows that it is far easier to find flaws or unsupported parts in someone else's theory or experiment, than to design a useful theory or experiment of one's own.
3.3 From observation to prediction: the role of models
A contribution to scientific knowledge is commonly judged by the same standard as a contribution in many other practical endeavors: how well does it allow us to predict future events or performance? By way of analogy, an investment counselor's financial advice is worthwhile to the extent that it yields future income, not by how well it would have worked in past markets. Other criteria might be applied in astronomy or geology, for instance, but prediction is the standard criterion.[3]
Investment counselors have an incentive to conceal part of the basis for their advice. After all, if you knew everything about how the advice was generated, you could avoid paying the counselor's fee, because you could get answers to your specific questions yourself. In contrast, one of the standard requirements for a contribution to scientific knowledge is that it must include details that permit others to predict future behavior for themselves. [4]
The form of a scientific prediction is a mathematical model. Here are some examples.
1. A stone is dropped from a window of every eighth floor of a tall building, that is from the 8th floor, from the 16th, from the 24th, and so on. As a stone is dropped from each floor, a stopwatch is used to measure the amount of time that elapses until it hits the ground. The following table tells the height of the window sill at each floor and the recorded times in the experiment:
| Floor | 8 | 16 | 24 | 32 | 40 |
|---|---|---|---|---|---|
| Distance to Ground (ft.) | 96 | 192 | 288 | 384 | 480 |
| Drop time (sec.) | 2.45 | 3.46 | 4.24 | 4.90 | 5.48 |
A good model for the relationship between dropping time t and the distance d is the mathematical function:
This rule certainly explains the recorded observations. You can easily verify that 16 x 2.45^2 = 96.04, and so on.
We attribute the discrepancy of .04 between the distance of 96.04 that our model associates with the dropping time of 2.45 seconds and the observed distance of 96 as measurement error. All of the other discrepancies are similarly small. For the time being, we will not be concerned with the process by which such incredibly precise measurements were made.
2. By supposing that the dropping time is related to the distance, we are avoiding what is often the hardest part of modeling: separating what is relevant from what is irrelevant. Suppose we had carefully recorded the length of the names of the person who dropped the stone from each floor. Here is another table, showing this previously overlooked relationship.
| Name of Dropper | YY | Sal | John | David | Kathy |
|---|---|---|---|---|---|
| Name Length | 2 | 3 | 4 | 5 | 5 |
| Drop time (sec.) | 2.45 | 3.46 | 4.24 | 4.90 | 5.48 |
If you round the dropping time to the nearest integer, the result is the same as the name length of the person who dropped the stone. In this case the function:
is a mathematical model for the relationship.
How do you decide which model is better? All other things being equal, you would probably prefer the first model for its advantage in precision. However, there is a better way to make the choice, which is to extend the experiment in such a way that the predictions of the two models disagree.
For instance, we might send a volunteer named Mike to the 60th floor, whose window is 720 feet from the ground. The first model predicts that the stone will drop in
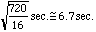
The second model predicts a dropping time of 3.5 to 4.5 seconds.
Sometimes, two different models make the same prediction for all of the possible cases of immediate interest. In that instance, the philosophical principle called "Ockham's razor" is applied, and the simpler model is regarded as preferable.[5]
The namelength model might seem a trifle too frivolous to have been seriously proposed; more frivolous, say, than the discredited phlogiston theory. However, we can turn it around to make a point. Often the best explanation of a phenomenon is initially in something the experimenter ignores because it is not the right kind of answer.
A chemist who is pouring solutions from test tube to test tube might not think that the effect being observed depends on whether the experiment is performed in natural light or artificial light. A physician whose clinical research is primarily on the same day every week might be completely unaware that the patients at the clinic on that day of the week differ from those who are there on other days.
When research findings are published, there is an opportunity for other persons to repeat the experiment. If different results are obtained on different occasions, an explanation is required. It is likely that other researchers will think of various ways to extend the experiment. Often they wish not only to test the results of another scientist, but also to have an opportunity to augment the model.
Not every mathematical model is given by a closed formula. Here is another example.
3. A pair of cuddly animals is kept together from birth. After one month, there is still only the original pair. However, after two months there is a second pair, after three a third. After four months there are five pairs. The following table shows the number of pairs for the first eight months:
| Time (months) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| Number of Pairs | 1 | 1 | 2 | 3 | 5 | 8 | 13 | 21 | 34 |
Notice that after two months, the number of pairs in any given month is the sum of the numbers of pairs one month ago and two months ago. For instance, the number of pairs at six months is 13, which is the sum of 8 and 5, the numbers at five months and at four months.
One possible model for this process is recursive. Let p(n) represent the number of pairs at n months. Then the value of p(n) for any positive integer n is given by this recursively defined function:
p(1) = 1
p(n) = p(n-1) + p(n-2) if n > 1
The following program calculates p(60), or rather it calculates an approximation to p(60) (the number p(60) is so large that it is represented in the computer in floating point form, with lower order digits truncated).
Program Fibonacci[6]
100 DIM P[60]
110 LET P[0] = 1
120 LET P[1] = 1
130 FOR N = 2 TO 60
140 LET P[N] = P[N-1] + P[N-2]
150 NEXT N
200 PRINT P[60]
Despite the recursive definition of the Fibonacci function, using a recursive program to calculate Fibonacci numbers is a bad mistake. Here is such a recursive program.
Function FIBONACCI (N)
FIBONACCI (0) = 1
FIBONACCI (1) = 1
FIBONACCI (N) = FIBONACCI (N-1) + FIBONACCI (N-2)
Imagine that you want to calculate the 60th Fibonacci number. The first recursive step:
"calls itself" twice. That is, its right side requires that the function Fibonacci be calculated for the arguments 59 and 58. Calculating FIBONACCI (59) and FIBONACCI (58) each require two more self calls, thus, an additional four calls. For each of those four calls, there would be two more self-calls. For each of those eight self-calls, there would be two more -- that is, 16 additional calls -- and so on, until the bottom level was reached. Thus, there would be exponentially many calls. Such a phenomenon is known as "exponential recursive descent". You would have to wait a very long time to see the answer.
3.4 Obstructions to measurement
Different kinds of obstruction to measurement are encountered in different categories of scientific research. In the physical sciences, perhaps the toughest problem is indirectness. For instance, how do you measure the duration of existence of a particle theoretically supposed to survive for a millionth of a second, assuming it really exists at all?
In the biological sciences, limitations on precision are also a formidable obstacle. If you have ever observed a human birth, you know how difficult it would be to assign a precise moment of birth. Of course, most human births are not the subject of scientific research; still, it is interesting to know how the time of birth is decided upon in many cases. Shortly after the infant receives the necessary immediate care, someone says, "Did anyone get the time of birth?", and someone else says, "Yes, it was xx:xx.", based on a rough estimate. While it might be possible in a research study to get somewhat more accurate times than those typically recorded, it would make no sense to try to record them to, say, the tenth of a second.
In this section, we will concern ourselves mainly with the frontiers of measurement in the sociological sciences. In addition to severe problems of semantics, competing special interests, and deliberate political obfuscation, there are questions of intrinsic measurability -- that is, whether a putative property can be measured at all.
Tax reform is a good example of a truly tangled issue. How do you measure the economic outcome on various classes of individuals that has accrued from an adopted reform? An obvious, oversimplified approach is to compute the tax burden for prototype individuals under both the new system and the old. The omitted complication is that when tax laws change, many individuals and businesses adapt their economic behavior. These primary adaptations have consequences for other taxpayers, who also adapt their behavior, in turn affecting other persons.
Moreover, the act of changing tax laws can cause alterations in social values, such as risk-taking behavior, charitable giving, and perception of personal needs. These changes in values can, in turn, have a major effect upon taxation under the reformed system. Even the possibility that major changes in tax laws could occur is likely to make some persons and businesses seek near-term results, instead of looking to the long run.
Even after tax laws are changed, it is difficult to distinguish whether subsequent changes in the economy are the result of the tax changes or of something else. There are times when we just don't have a trustworthy way to make a measurement, often because so many factors affect the observable outcome that it is hard to sort out what is due to a particular change.
For another preliminary example, consider two persons who are largely in control of what they do at their jobs. Perhaps they are both primarily responsible for administrative work. They are arguing one day about who is "busier" than the other. One says her calendar is packed from morning to night with appointments to keep and things that must be done, and that since there are no breaks in it whatsoever, no one else could possibly be busier without working an even longer day. The other counters that her day is so much busier, she is constantly having extemporaneous meetings and taking phone calls, and she doesn't even have the time for "non-productive" activities like making schedules to protect herself from interruptions. Underlying this slightly frivolous dispute are two competing theories of measurement of busyness. The first administrator is suggesting that if someones time is completely allocated in advance, then that person is 100% busy. The second is suggesting that busyness is related to the number (and also, perhaps, to the intensity) of interruptions. As in the case of tax reform, we have no resolution to propose.
The Alabama paradox A less complicated measurement quandary, in the sense that there are fewer factors involved, is caused by the problem of apportionment in the House of Representatives of the United States. To give a simplified illustration of a phenomenon known as the "Alabama paradox", we will reduce it to a model with four states, known as A, B, C, and D, a population of 100 million persons, and 30 representatives to be apportioned. The following table gives the population of each state, and its exact proportion of the population, expressed as a decimal fraction to three places:
| State | Population | Proportion |
|---|---|---|
| A | 4,500,000 | .045 |
| B | 10,700,000 | .107 |
| C | 31,100,000 | .311 |
| D | 53,700,000 | .537 |
| Totals: | 100,000,000 | 1.000 |
Since there are 30 representatives, the first step in calculating the fair share for each state is to multiply its proportion of the total population by 30. The next table shows the result of this calculation:
| State | Proportion | Exact Fair Share |
|---|---|---|
| A | .045 | 1.35 |
| B | .107 | 3.215 |
| C | .311 | 9.33 |
| D | .537 | 16.11 |
| Totals: | 1.000 | 30.00 |
It is obvious that State A should get at least 1 representative, State B at least 3, State C at least 9, and State D at least 16, but that makes only 29 representatives, so there is one leftover. What once seemed obvious to all was that State A should get the remaining representative, because its remaining fraction of 0.35 is the largest fraction among the four states. If there were two remaining representatives after each state got its whole-number share, then the state with the second largest fractional part -- in this case, State C, with 0.33 -- would get the second remaining representative, and so on.
Now imagine that the number of representatives is increased from 30 to 31. You might guess that the additional representative will go to State C, but what happens is far more surprising. Here is a new table of exact fair shares, based on 31 representatives:
| State | Proportion | Exact Fair Share |
|---|---|---|
| A | .045 | 1.39 |
| B | .107 | 3.32 |
| C | .311 | 9.64 |
| D | .537 | 16.65 |
| Totals: | 1.000 | 31.00 |
The integer parts of the fair share calculations remain the same as they were in the 30 representatives case, and they add to a total of 29. However, the two remaining representatives go to State D (with the highest fractional part, at 0.65) and to State C (with the second highest fractional part, at 0.64). Thus, increasing the number of representatives has had the "paradoxical" effect of costing State A one of its representatives.
When this first occurred in United States political history, the "victim state" was Alabama, hence the name "Alabama paradox". Later, Maine was a losing state.
In the 1970's, two mathematicians, M. Balinski and H. P. Young, devised a different way to achieve "proportional representation", in which each state would still get at least its whole-number share, and such that no state would ever lose a representative to the Alabama paradox. The principal disadvantage of this innovative plan is that scarcely any non-mathematicians are able to understand how to use it.
Certain countries, notably France, have resolved the problem by assigning fractional votes to certain representatives. It has also been argued that the Alabama paradox is not unfair, since it merely removes a temporary partially unearned seat from one state and transfers it to another. In practice, however, it is clear that some states have ganged up on others and contrived to increase the number of representatives in such a manner as to deprive particular persons of their seats.
The Condorcet paradox . Another issue that has arisen in the political realm presents a deeper problem. Suppose that there are several candidates for the same office, and that each voter ranks them in the order of his or her preference. It seems to stand to reason that if one candidate is a winner, then no other candidate would be preferred by a majority of the voters. Now suppose there were three candidates, known as A, B, and C, a population of 100 voters, and that the following distribution of rank orders was obtained.
| Ranking Order | Number of Voters |
|---|---|
| A > B > C | 32 |
| B > C > A | 33 |
| C > A > B | 35 |
| Total: | 100 |
From this table, it seems to follow that:
This paradox is not an indictment of the concept of rank-order voting. Under most common vote-for-one-only systems, a winner would emerge, but not one with a "clear mandate". For instance, if the winner were determined by plurality on the first ballot, then Candidate C would win, despite the fact that 65% really would have preferred Candidate B. Just because the vote-for-one-only system conceals this preference doesn't change the actuality that it is indeed a preference of the voters. If the rules called for elimination of a least favored on each round until one candidate obtained a plurality, then Candidate A would be eliminated on the first round, and Candidate B would get the 32 votes no longer assignable to Candidate A. Thus, Candidate B would win, even though 67% of the voters would have preferred Candidate A.
The underlying measurement problem here is as follows: given a rank order preference list supplied by each voter, how do you determine the "collective choice"? The area of applied mathematics in which this problem is studied is called "social choice theory", and one of its practitioners, Kenneth Arrow, has won a Nobel Prize in Economics for showing that no method of choosing a winner could simultaneously satisfy all the reasonable constraints one would wish to impose and still work in every instance.
Perhaps the strongest aspect of vote-for-one-only systems is that they are easily understood and difficult to manipulate by voter-bloc discipline. Under political conditions in which voters commonly feel that the problem is choosing the "least undesirable candidate", since no desirable candidate exists, it is sometimes suggested that voters should have the option of voting "no" against their least-liked candidate, where a yes counts +1 and a no counts -1. There is both a "yes-or-no" system, in which one may vote either "yes" for a most-favored candidate or "no" against a least-liked, but not both, and a "yes-and-no" system in which one may make both a "yes" vote and a "no" vote. A prominent advantage of such a system is that "protest-voters" would not end up "wasting" their votes on obscure candidates with no chance of winning. Nonetheless, "no"-vote systems have problems of their own, and this is explored in some of the exercises below.